🌴 バミューダの暗号革命: 島の生活とブロックチェーンの大成功が出会う! 🚀
ジューシー ビッツ (ダール風のお楽しみを少々):
🎩 クリプトのグランド・マスカレード: ジャック・ルーのスーパーサイクル・ソワレ 🎲
ああ、Magic Eden の CEO 兼共同創設者である Jack Lu が、ビクトリア朝のダンディのセンスを備えた新しいトークン買い戻しプログラムを発表しました。 「当社の収益の 15% は自社株買いと USDC 利回りで分配されます」と彼は宣言します。そしてなぜですか?なぜなら、金融とエンターテイメントが下手に混ぜ合わされたカクテルのように融合する「投機スーパーサイクル」に私たちは突入しているからです。 🍸
香港の仮想通貨カオス! 🤯

月曜日、いつもと同じように、静かな生存の絶望に満たされた日、金融に苦しむ人々の集まりである香港証券先物専門家協会(HKSFPA)は、OECDの暗号資産報告フレームワーク(CARF)の実施と香港の共通報告基準(CRS)の修正に関する声明を発表した。当然の反応。なぜなら、避けられない書類手続きの波に直面したときに、 他に何をするのでしょうか?
Pump.fun の 300 万ドルのハッカソン: トークンファンディングは VC のドラマに取って代わることができますか? 🤑🚀

Pump.fun は、スタートアップの資金調達方法を変える、300 万ドルの Build in Public (BiP) ハッカソンを発表しました。その新しい投資部門であるポンプ・ファンドの支援を受けているこのプログラムは、初期段階のプロジェクトがよりシンプルかつオープンな方法で資金を調達できるように支援するもので、報道機関の表現を借りれば「金融の民主化」(つまり、全員が一緒にお金を失うことができる)と言えるでしょう。 💸
DeFi ドラマ: 1,299 ETH はマラソンのカタツムリより速く消えます!
探偵小説にふさわしいどんでん返しで、悪役は 1 回の取引で 1,299 ETH を引き出しました。 PeckShield の友人たちは、トランザクション実行中に卑劣な攻撃者が鋭い MEV ビルダーに出し抜かれたと報告しました。これはブロックチェーンのブロックの複雑さを考えさせられる啓示です。
NYSEの新しいブロックチェーンバンドル:24時間365日取引?本当に?

このプラットフォームは、24 時間体制のオペレーション、即時決済、および 1 ドル規模の注文を提供します。なぜなら、不安で眠れない午前 3 時にトレードできることほど「革新」と言えるものはないからです。 🕯️
ペンドルのステーキング変身: 2.35 ドルの抵抗は失われるか? 🎉💸
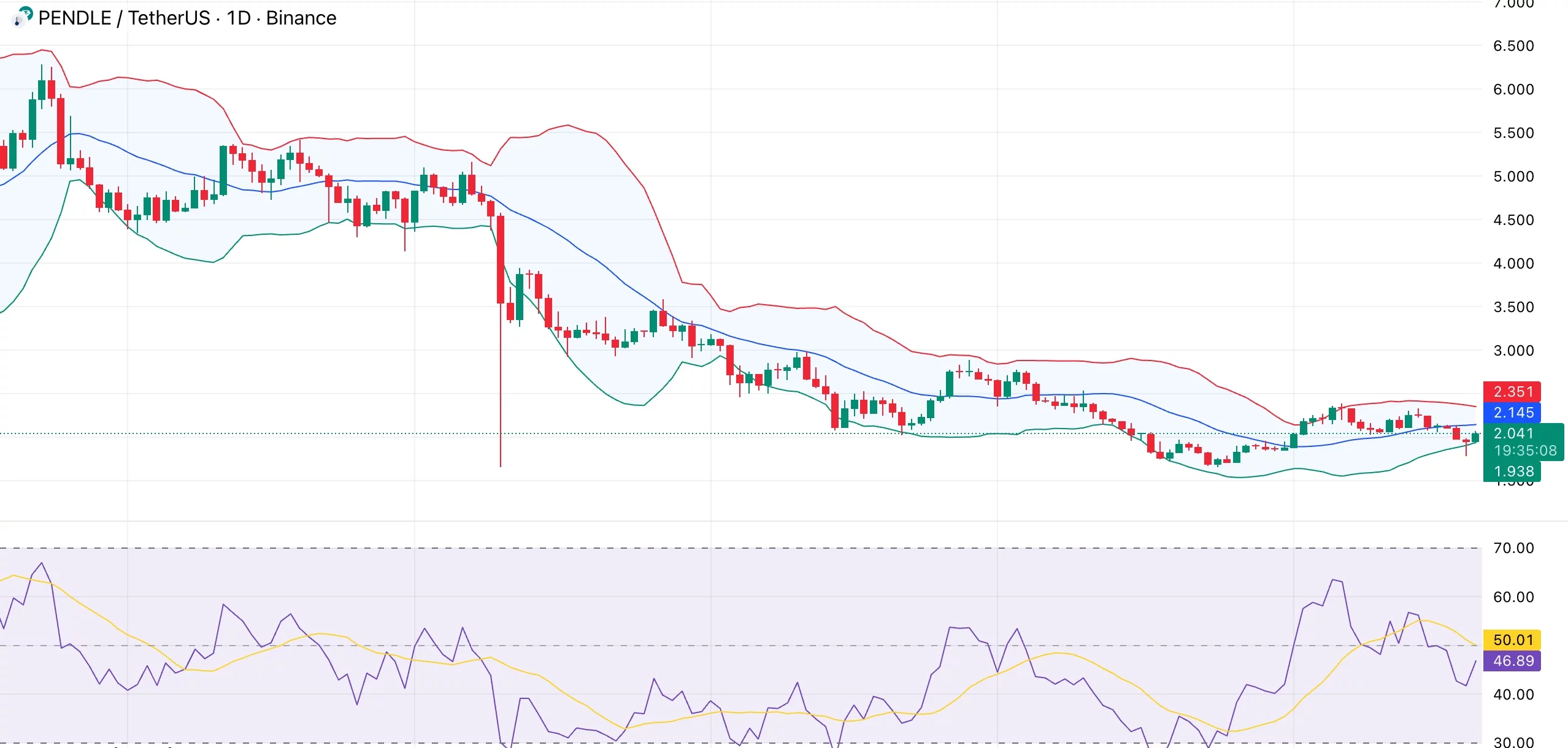
つまり、ペンドルの取引価格は 2.07 ドルで、過去 24 時間で 9% 上昇しました。大騒ぎですよね?間違っている。これは単なるランダムなノイズではなく、誰もが注目するトケノミクスの見直しです。 🧐 2.35 ドルの抵抗レベルは、学校のクールな子供のようなもので、ペンドルはそのテーブルに座ろうとしています。
韓国で仮想通貨洗浄業者が素人同様に逮捕される 🤦♂️

韓国の外為法があなたの「創造的な会計」方法を評価していないため、現在3人が公式にトラブルに見舞われています。正直に言うと、仮想通貨取引を追跡するのは絵の具が乾いていくのを見るのと同じくらい楽しいので、調査には何年もかかりました。 🥱
🤑 仮想通貨の暴走: 数十億の流入、数百万の流出 – 責任はグリーンランドにある? 😱
この突然の逆転の原因は?グリーンランドをめぐる外交的緊張、新たな貿易関税の脅威(何とうんざりすることだろう!)、そして政策ハト派として注目を集めているケビン・ハセット氏が米連邦準備理事会(FRB)議長という崇高な地位に昇進するのではなく、現在の役職に留まるというニュースにほかならない。これが高級金融機関の応接室でどれほどの混乱を引き起こしたかは想像するしかありません。